论文链接:https://arxiv.org/pdf/2503.19786
代码链接:
摘要
我们推出了 Gemma 3,它是 Gemma 系列轻量级开放模型中的多模态新成员,其规模从 1B 到 27B 参数不等。此版本引入了视觉理解能力、更广泛的语言覆盖范围和更长的上下文——至少 128K 个 token。我们还更改了模型架构,以减少键值缓存(KV-cache)的内存占用,因为长上下文往往会使其爆炸式增长。这是通过增加局部注意力层与全局注意力层的比例,并保持较短的局部注意力跨度来实现的。Gemma 3 模型经过蒸馏训练,无论是预训练版本还是指令微调版本,其性能都优于 Gemma 2。值得一提的是,我们创新的后训练方案显著提升了数学、聊天、指令遵循和多语言能力,使 Gemma3-4B-IT 在各项基准测试中与 Gemma2-27B-IT 相媲美,而 Gemma3-27B-IT 则与 Gemini-1.5-Pro 相媲美。我们已将所有模型发布给社区。
1.介绍
我们推出了 Gemma 开放语言模型的最新版本,该模型与 Gemini Frontier 模型系列共同设计。新版本的大小与 Gemma 2 相当,并增加了一个 1B 模型。这些模型旨在在标准消费级硬件上运行,例如手机、笔记本电脑和高端 GPU。此版本为 Gemma 系列带来了多项新功能,即多模态、长上下文和多语言性,同时保留或超越了先前版本的性能。
在多模态方面,大多数 Gemma 3 模型都兼容定制版 SigLIP 视觉编码器。语言模型将图像视为由 SigLIP 编码的软 token 序列。我们通过将视觉嵌入压缩为 256 个向量的固定大小来降低图像处理的推理成本。编码器以固定分辨率工作,我们借鉴 LLaVA 的灵感,通过平移和扫描 (P&S) 方法实现了灵活的分辨率。
第二个主要的架构改进是将上下文大小增加到 128K 个 token,同时不降低性能。长上下文的一个挑战是推理过程中键值缓存的内存爆炸。为了解决这个问题,我们在每个全局层之间交错放置了多个局部层,并为局部层分配了较小的跨度,仅为 1024 个 token。因此,只有全局层负责处理长上下文,并且每 5 个局部层对应 1 个全局层。
预训练优化方案与 Gemma 2 类似,但在架构设计上有所修改。我们使用与 Gemini 2.0 相同的 tokenizer,并重新审视数据混合,以提升模型的多语言能力,同时引入图像理解功能。所有 Gemma 3 模型均采用知识蒸馏进行训练。
在后训练阶段,我们专注于提升数学、推理和聊天能力,并整合 Gemma 3 的新功能、长上下文和图像输入。我们采用一种新的后训练方法,全面提升了数学、编程、聊天、指令遵循和多语言等各项能力。由此产生的 Gemma 3 指令调优模型既强大又灵活,性能远超前代产品。
在以下章节中,我们将简要概述我们的模型,包括其架构以及预训练和后训练方案。我们还提供了基于各种定量和定性基准的详细评估。我们讨论了安全且负责任的部署方法,并概述了 Gemma 3 的广泛影响、局限性和优势。
2.Model Architecture
Gemma 3 模型遵循与前几代相同的通用解码器专用 Transformer 架构,大多数架构元素与前两代 Gemma 版本相似。我们使用了以 RMSNorm 实现的带有 post-norm 和 pre-norm 的分组查询注意力机制 (GQA)。受 Dehghani et al. (2023),Wortsman et al. (2023) 和 Chameleon Team (2024) 的启发,我们用 QK-norm 取代了 Gemma 2 中的 soft-capping。本节将重点介绍与前两代 Gemma 的一些主要区别。
5:1 interleaving of local/global layers。我们在局部滑动窗口自注意力和全局自注意力之间交替,每个全局层有 5 个局部层,并以局部层作为模型的第一层。
Long context。Gemma 3 模型支持 128K 个 token 的上下文长度,但 1B 模型除外,其长度为 32K。我们将全局自注意力层的 RoPE base 从 10k 提升至 1M,并将局部层的 base 保持在 10k。我们采用类似于 Chen et al. (2023) 的位置插值方法来扩展全局自注意力层的跨度。
2.1 Vision modality

Vision encoder。我们使用了 SigLIP 编码器的 400M 变体,这是一个使用 CLIP 损失函数变体训练的 Vision Transformer。Gemma 视觉编码器以调整大小至 896 x 896 的方形图像作为输入,并根据视觉助手任务的数据进行微调。为简单起见,我们在 4B、12B 和 27B 模型之间共享视觉编码器,并在训练期间保持其冻结状态。
Pan & Scan (P&S)。Gemma 视觉编码器的分辨率固定为 896 × 896。这会导致在处理非正方形长宽比和高分辨率图像时出现伪影,导致文本无法阅读或小物体消失。我们在推理过程中使用自适应窗口算法来解决这个问题。该算法将图像分割成大小相等、互不重叠的裁剪区域,覆盖整个图像,然后将其调整为 896 × 896 像素以传递给编码器。此窗口仅在必要时应用,并控制最大裁剪区域数量。这是一种仅适用于推理时间的优化,可以禁用以加快推理速度。
2.2 Pre-training
我们遵循与 Gemma 2 类似的方法进行知识蒸馏的预训练。
Training data。我们采用比 Gemma 2 略大的 token 预算对模型进行预训练,例如,Gemma 3 27B 使用 14T token进行训练,12B 版本使用 12T token,4B 版本使用 4T token,1B 版本使用 2T token 进行训练。token数量的增加解释了预训练过程中图像和文本的混合使用。我们还增加了多语言数据量,以提高语言覆盖率。我们添加了单语数据和并行数据,并使用受 Chung et al. (2023) 启发的策略来处理语言表征的不平衡问题。
Tokenizer。我们使用与 Gemini 2.0 相同的 tokenizer:SentencePiece tokenizer,它支持拆分数字、保留空格和字节级编码。最终生成的词表为 262k 。此 tokenizer 对于非英语语言而言更加均衡。
Filtering。我们使用过滤技术来降低不受欢迎或不安全的言论风险,并删除某些个人信息和其他敏感数据。我们从预训练数据混合中净化评估集,并通过最大限度地减少敏感输出的扩散来降低被引用的风险。我们还采用了受 Sachdeva et al. (2024) 启发的质量重加权步骤,以减少低质量数据的出现。
Distillation。我们为每个 token 采样 256 个 logits,并按 teacher 概率加权。student 通过交叉熵损失学习这些样本中的 teacher 分布。对于未采样的 logits,teacher 的目标分布设置为零概率,并进行重新归一化。
2.3 Quantization Aware Training
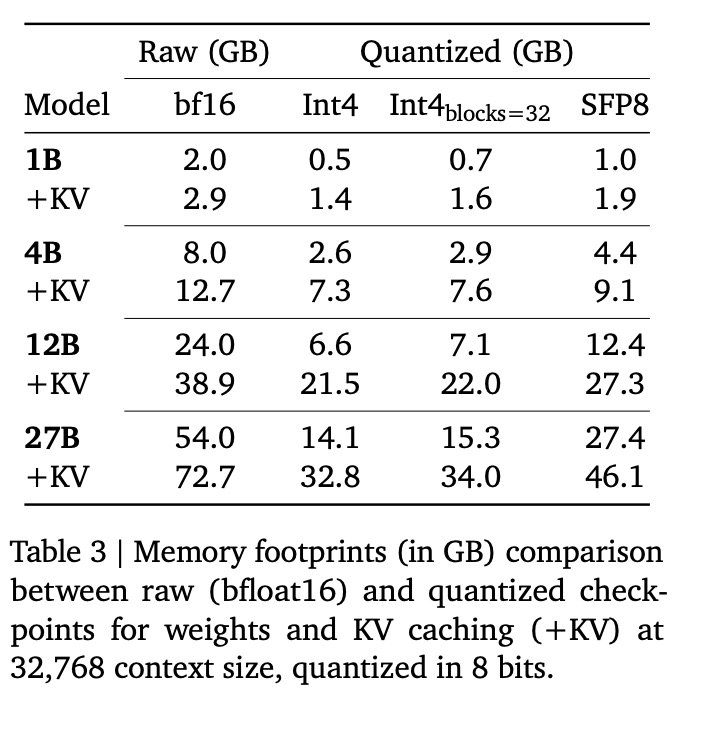
除了原始 checkpoint 外,我们还提供不同标准格式的模型量化版本。这些版本是通过使用量化感知训练 (QAT) 对每个模型进行少量步长(通常为 5,000 步)微调而获得的。我们使用非量化 checkpoint 的概率作为目标,并调整数据以匹配训练前和训练后的分布。基于最流行的开源量化推理引擎(例如 llama.cpp),我们专注于三种权重表示:每通道 int4、每块 int4 和交换 fp8。在表 3 中,我们报告了原始模型和量化模型在有和无 KV 缓存的情况下,对 32k 个 token 序列的每个权重表示所占用的内存。
2.4 Compute Infrastructure
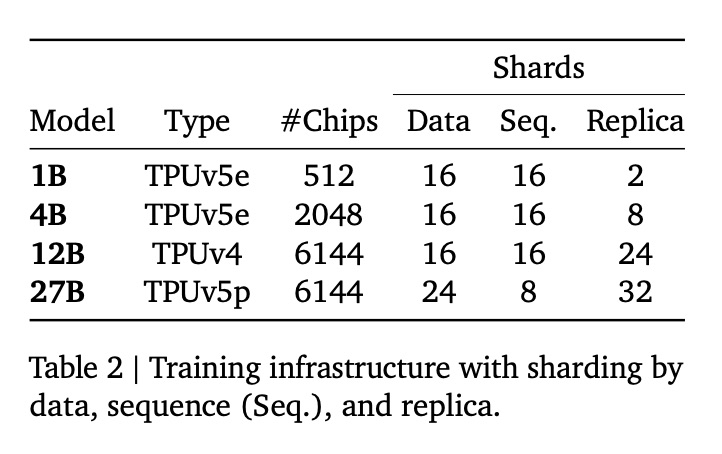
我们使用表 2 中列出的 TPUv4、TPUv5e 和 TPUv5p 训练模型。每种模型配置都经过优化,以最大程度地缩短训练步骤时间。对于视觉编码器,我们预先计算每幅图像的嵌入,并直接使用这些嵌入进行训练,这不会增加语言模型的训练成本。
优化器状态使用 ZeRO-3 的实现进行分片。对于多 Pod 训练,我们使用 Barham et al. (2022) 的 Pathways 方法,通过数据中心网络执行数据副本缩减。我们使用 Jax 和 Pathways 的“单控制器”编程范式,以及 GSPMD 分区器和 MegaScale XLA 编译器。
3.Instruction-Tuning

与我们之前的方法相比,预训练模型通过改进的后训练方法转变为指令微调模型(见表 6)。
Techniques。我们的后训练方法依赖于来自大型 IT teacher 的改进版本的知识蒸馏,以及基于改进版本的 BOND、WARM 和 WARP 的 RL 微调阶段。
Reinforcement learning objectives。我们使用各种奖赏函数来提升模型的实用性、数学、编码、推理、指令遵循和多语言能力,同时最大限度地降低模型的危害性。这些函数包括使用人工反馈数据、代码执行反馈以及用于解决数学问题的标准值奖赏训练的加权平均奖赏模型。
Data filtering。我们精心优化了后训练使用的数据,以最大限度地提升模型性能。我们会过滤掉那些包含特定个人信息、不安全或有害的模型输出、错误的自我认同数据以及重复的样本。此外,我们还会添加一些数据子集,以鼓励更好地进行情境归因、进行对冲以及拒绝减少幻觉,这也能提升模型在事实性指标上的表现,而不会降低模型在其他指标上的表现。
[BOS] token。对于 PT 和 IT 模型,文本都以 [BOS] token开头,由于文本“[BOS]”不映射到 [BOS] token,因此需要显式添加该token。例如,Flax 有一个选项 add_bos=True,可以在 tokenizer 时自动添加此token。表 4 显示了 IT 模型的格式示例。
PT versus IT Formatting。所有模型共享相同的 tokenizer,并有一些控制 tokenizer 专门用于 IT 格式。一个关键区别在于,PT 模型在生成结束时输出一个 token,而 IT 模型在生成结束时输出一个 token,如表 4 中 IT 所示。因此,对任一模型类型进行微调也需要添加各自的结束分词器。
4.Evaluation of final models
在本节中,我们将通过一系列自动化基准和跨多个领域的人工评估以及 MMLU 等静态基准来评估 IT 模型。
4.1 LMSYS Chatbot Arena
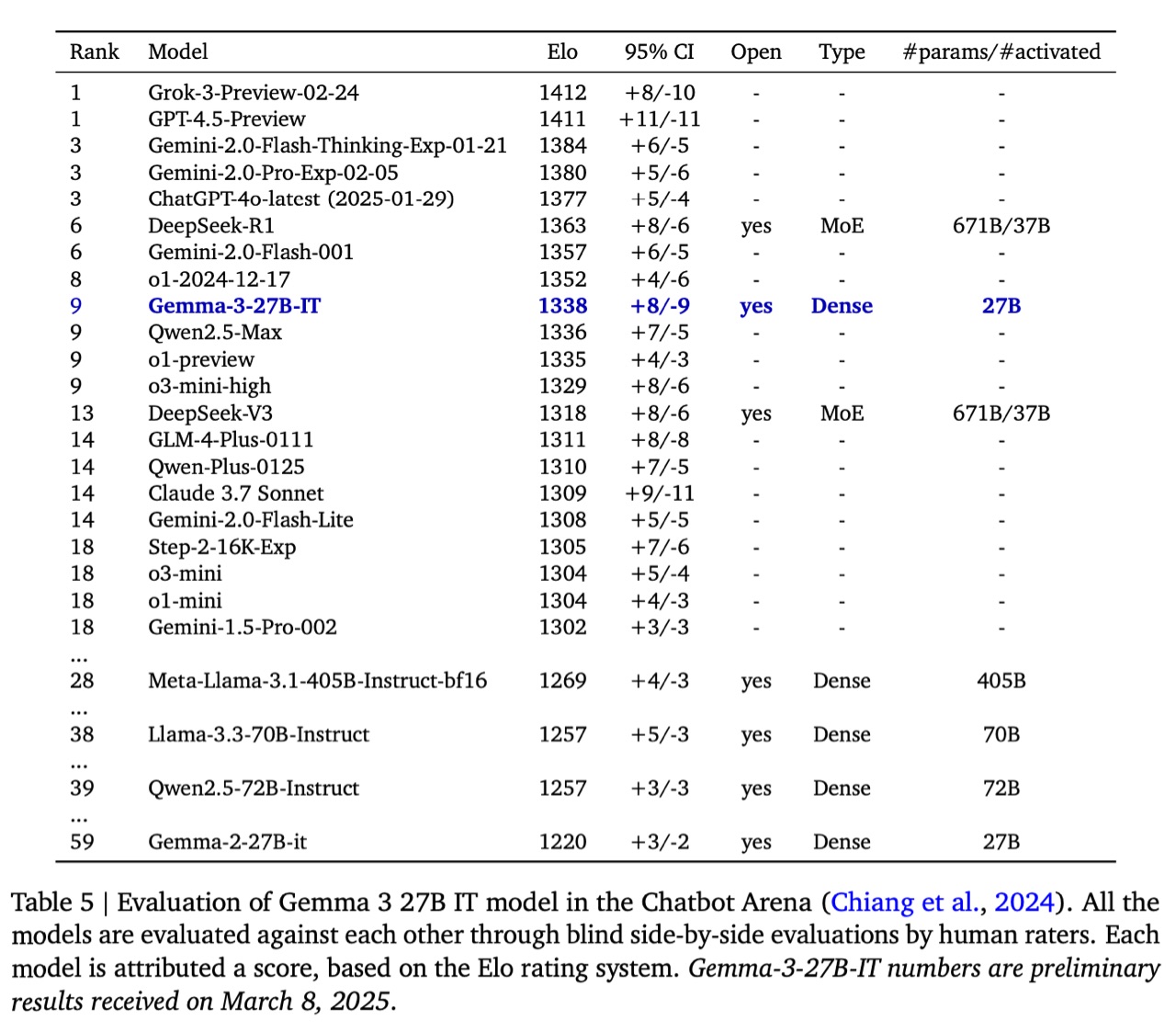
在本节中,我们将报告 IT 27B 模型在 LMSys Chatbot Arena 上的表现,该模型由人工评分员进行盲测,并与其他最先进模型进行并排评估。表 5 中列出了 Elo 分数。Gemma 3 27B IT (1338) 位列十大最佳模型之列,其得分高于其他非思考开放模型,例如 DeepSeek-V3 (1318)、LLaMA 3 405B (1257) 和 Qwen2.5-70B (1257),这些模型的规模要大得多。最后,Gemma 3 的 Elo 分数为 1220,显著高于 Gemma 2。需要注意的是,Elo 分数未考虑视觉能力,而上述模型均不具备视觉能力。
4.2 Standard benchmarks
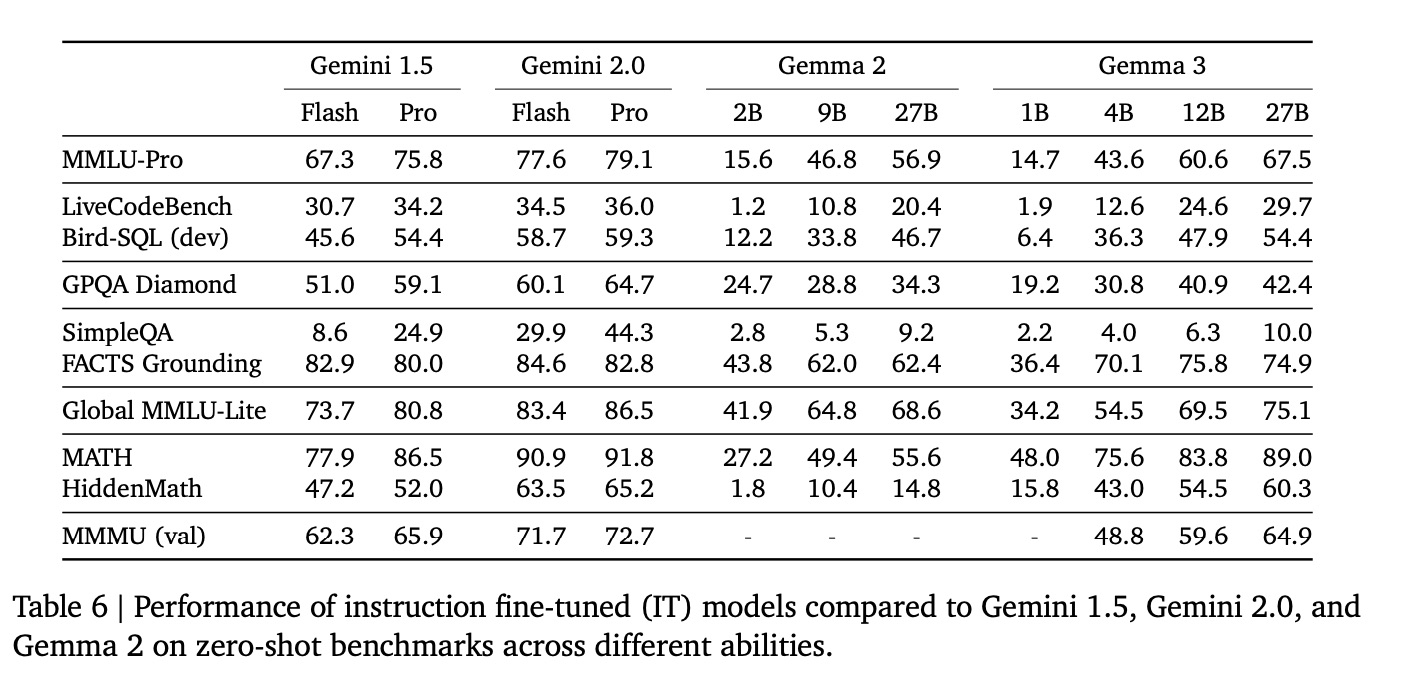
在表 6 中,我们展示了最终模型在各种基准测试中的表现,并与之前的模型迭代和 Gemini 1.5 进行了比较。我们不会直接与那些经常报告自身评估设置的外部模型进行比较,因为在我们的设置下运行它们并不能保证公平的比较。我们鼓励读者关注第三方静态排行榜,以便对各个模型进行更公平的比较。附录中还包含我们模型在其他基准测试中的评估结果。